接續上一篇文章「 Rails 在 Mac 設定開發環境 」,現在你的開發環境已經準備好了,讓我們開始構建 API 專案,我將描述建立一個僅 Rails API 的應用程式,以及使用 Rails Generator 使得開發變得容易和快速,是改進工作流程的重要工具,讓開發人員可以專注於做內部業務邏輯。
建立一個新的 Rails 專案
使用 rails new 快速產生第一個 Rails 專案,為了產生以 API 為中心的框架,使用 --API flag 可以排除在其他情況下不會使用或不必要的功能。
- 裝載較少的 Middleware
- ApplicationController 繼承自 ActionController::API 而不是 ActionController::Base
- 跳過生成 views, helpers, and assets
rails new restful-api --api --skip-active-storage --skip-action-mailer --skip-action-mailbox -T使用命令 -T 將跳過 Minitest::Unit 文件和文件夾的生成,我們之後將使用 RSpec 作為測試而不是 MiniTest。
啟用 CORS(跨域資源共享)
CORS 是一個瀏覽器做跨網域連線的安全機制,透過 HTTP header 的設定,可以規範瀏覽器在進行跨網域連線時可以存取的資料權限與範圍,包括哪些來源可以存取,或是哪些 HTTP verb, header 的 request 可以存取。
為了防止對您的 API 進行不必要的訪問,Rails 會自動禁用 CORS。
開啟 Gemfile 檔案取消 rack-cors 註解:
gem 'rack-cors'並在 terminal 中,運行 bundle install 更新專案套件:
bundle install為簡單起見,將允許所有來源可以存取。
更新 config/initializers/cors.rb 以允許所有來源 (*) 發出請求。
Rails.application.config.middleware.insert_before 0, Rack::Cors do
allow do
origins '*'
resource '*',
headers: :any,
methods: [:get, :post, :put, :patch, :delete, :options, :head]
end
end通過 Rails generators 命令建立資源
Rails 提供了很多 Generators 指令快速建立:model、controller、test 和 route 文件,然後復製到專案目錄中,多虧了 rails generate 讓開發者不必考慮架構配置的負擔,立即開始實現專案功能。
在這篇文章中,我們將使用以下需求:
- 用戶、 訂單
- 一個用戶可以有很多訂單
我們使用 rails generate resource 建立,它將為我們產生 model、controller、migrate。
# 產生用戶相關資源
rails generate resource User
# 產生訂單相關資源
rails generate resource Order執行後將看到該命令一舉建立了以下文件:
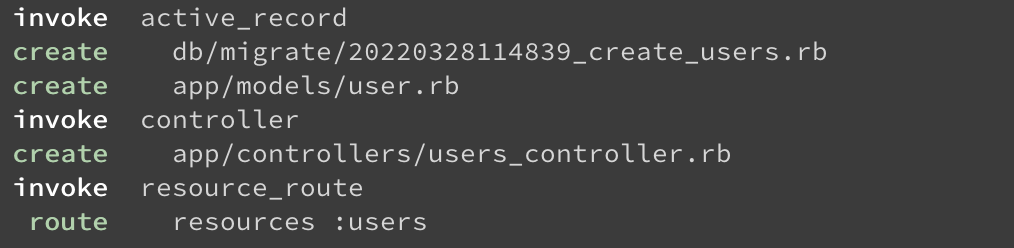
定義資料表結構
當構建專案時,我們需要對數據庫進行更改可能是增加資料表、增加欄位、修改欄位類型、增加索引等 ⋯⋯ Rails 中的 Migration 允許我們撰寫 Ruby 程式來對數據庫進行這些更改,與撰寫 SQL 語法更改相比,使用 Rails Migration 撰寫 DDL 有幾個優點:
- 與數據庫無關,可以在 SQLite3、PostgreSQL 和 MySQL 上面執行。
- 修改數據庫模式以版本控制的方式更好團隊協作開發。
接著可以在目錄 db/migrate 找到資料表定義用的檔案,打開檔案並增加以下代碼:
# db/migrate/20220328114839_create_users.rb
class CreateUsers < ActiveRecord::Migration[7.0]
def change
create_table :users do |t|
t.string :email
t.string :name
t.timestamps
end
end
end
# db/migrate/20220405101628_create_orders.rb
class CreateOrders < ActiveRecord::Migration[7.0]
def change
create_table :orders do |t|
t.references :user, index: true
t.integer :price
t.timestamps
end
end
end在 Terminal 中運行以下命令:
rails db:migrate你會得到類似這樣的輸出:
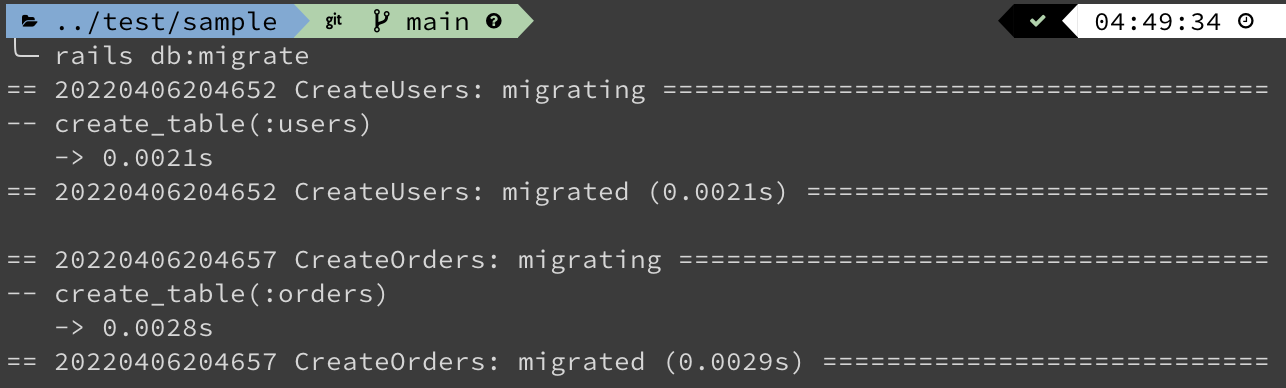
設定 Models 關係類型與資料驗證
在 Rails 中使用 ActiveRecord 形式的 ORM (Object Relational Mapping) 作為 Model 層,Active Record 提供的許多方法,讓開發者通過這些方法操作著資料庫裡的資料而不需要撰寫 SQL 語句,同時也支援了很多種資料庫系統,例如從 SQLite3 切換到 MySQL 而無需在調整語法就可以輕鬆更換。
在目錄 app/models 找到我們剛剛使用 rails generate 命令建立的 Model 檔案:
# app/models/user.rb
class User < ApplicationRecord
end
# app/models/order.rb
class Order < ApplicationRecord
end首先了解 Rails Model 如何對應資料表
Model 名稱遵循著 Ruby 的命名規則,Rails 會將 class 名稱轉成複數來找到對應的資料表,如果是需要不同於 Active Record 所提供的命名慣例,可以覆寫命名方法:
class User < ApplicationRecord
self.table_name = "users"
end但是如果有許多資料表在它們的名稱中只有相同的前綴,就要在每個 Model 中命名資料表名,為了改善程式,我們可以使用 table_name_prefix 方式。
所以首先我們可以創建一個 module Thirdparty 並設置一個 table_name_prefix 以 thirdparty_在使用該 module 時增加到資料表名稱之前:
# app/models/thirdparty.rb
module Thirdparty
def self.table_name_prefix
'thirdparty_'
end
end並使用 namespace Thirdparty 設定 Model Order :
# app/models/tw/city.rb
module Thirdparty
class Order < ApplicationRecord
end
end對於與表名中具有相同前綴的 Model,可以很方便的通過這個方法,幫助我們在程式中不重複。
宣告 Model 之間的關聯
在專案設計時數據資料表通常相互關聯,而將這些關聯在Rails 的世界裡連結起來,就可以使用 ActiveRecord 提供的方法簡化了常見的操作,省去大量與資料庫互動的部分。
在這篇文章需求中我們目標讓每個用戶可以擁有很多訂單,而每筆訂單只屬於一個用戶,因此在 User Model 使用 has_many 來宣告一對多的關係,而在 Order Model 使用 belongs_to 聲明屬於一個 User Model,完整程式的部分:
has_many - 告訴 Rails 每個用戶會有多筆訂單:
# app/models/user.rb
class User < ApplicationRecord
has_many :orders, dependent: :destroy
endbelongs_to - 告訴 Rails 每個訂單都屬於一個用戶:
# app/models/order.rb
class Order < ApplicationRecord
belongs_to :user
end在 User Model 中另外設定 dependent: :destroy 此選項,這可以幫助我們再刪除用戶時連同關聯的訂單資料也一併刪除。
定義儲存資料的驗證
在將資料儲存到資料庫之前,使用 Active Record Validations 來驗證數據屬性,如果這些驗證產生任何錯誤 Rails 將不會儲存,為 Model 提供了額外的安全層,確保寫入的資料是符合規定的。
假設需求是要求用戶填寫的電子郵件是有效,此外如果沒有填寫名字就無法建立用戶,現在我們在 Model 裡加上這些需求的驗證規則,可以這樣寫:
# app/models/user.rb
class User < ApplicationRecord
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-]+(\.[a-z\d\-]+)*\.[a-z]+\z/i.freeze
validates :email, presence: true, length: { minimum: 10, maximum: 255 },format: { with: VALID_EMAIL_REGEX },uniqueness: { case_sensitive: false }
validates :name, presence: true, length: { minimum: 3, maximum: 25 }
has_many :orders, dependent: :destroy
end驗證最常用的選項 presence: true 用來檢查此欄位是否為空值,這裏的空值是 nil 或者空字串都會被限制,以及使用 length 限制資料的長度,並且利用 format 正則表達式模式驗證電子郵件格式判斷是否有效,最後加上 uniqueness: (case_sensitive: false) 避免在驗證電子郵件時區分大小寫。
# app/models/order.rb
class Order < ApplicationRecord
belongs_to :user
validates :user, presence: true
end如果在關聯性之間更謹慎一點,可以在 belongs_to 的那個欄位後面,再寫一次 presence: true,如此一來不只檢查 foreign_key 是不是空值,還會檢查這筆引用的對像是否真的存在。
處理 REST Client 請求和響應
REST API 透過遵循 HTTP Method (GET、PUT、POST 和 DELETE) 來識別提供不同功能,指的是讀取、更新、建立和刪除有關資源的操作。
定義提供的服務
首先,我們擬定提供的 API 將具有以下端點:
GET /users/{id} 將接受 GET 請求並通過 id 返回指定的用戶
POST /users 將接受 POST 請求建立一筆新的用戶記錄
POST /users/{user_id}/orders 將接受 POST 請求並通過 user_id 建立一個指定用戶的訂單
編寫 Controller
在目錄中 app/http/controllers 找到名為 users_controller.rb 的檔案,編寫查詢指定用戶的邏輯,讓我們來實現它:
# app/http/controllers/users_controller.rb
class UsersController < ApplicationController
# GET /users/{id}
def show
if user
render json: user
else
render json: user.errors
end
end
private
def user
@user ||= User.find(params[:id])
end
end在上面的程式碼中,建立了一個 private user 方法,在這個方法中使用 ActiveRecord 的 find 與 API 端點中提供的 id 查詢相匹配的用戶,並將其用戶給實例變數(Instance Variable) @user,在 show action 中檢查 user 方法是否有傳回用戶並將以 JSON 格式響應結果,若如果不存在,則發送錯誤。
private user 方法中使用了 ||= 邏輯運算符號將 if 邏輯簡化,方法相當於:
def user
if @user
return @user
else
@user = User.find(params[:id])
return @user
end
end接下來,建立新用戶的邏輯,與查詢指定用戶一樣,將依賴 ActiveRecord 來驗證和儲存提供的用戶資料,再次更新 users_controller.rb:
# app/http/controllers/users_controller.rb
class UsersController < ApplicationController
# GET /users/{id}
def show
if user
render json: user
else
render json: user.errors
end
end
# POST /users
def create
user = User.create!(user_params)
if user
render json: user
else
render json: user.errors
end
end
private
def user_params
params.permit(:name, :email)
end
def user
@user ||= User.find(params[:id])
end
end在 create action 中,使用 ActiveRecord 的 create 建立一個新用戶,並通過使用 Rails 提供的 Strong Parameters 的特性來防止被惡意傳入的可能性,這樣除非有指定的參數才會被傳入,否則將會過濾掉。
我們建立了一個 private user_params 方法,只允許傳回 name, email 參數資料,將這個方法作為 create 的參數,以防止錯誤或惡意內容進入數據庫。
在執行 ActiveRecord create 的時候也將會觸發 Active Record Validations 定義的條件規則,在執行驗證後,如果提供的資料與任何一個規則不匹配時,將會引發錯誤與通過 errors 實例方法訪問傳回的錯誤集合。
最後,找到名為 orders_controller.rb 的檔案,編寫建立用戶訂單的邏輯:
# app/http/controllers/orders_controller.rb
class OrdersController < ApplicationController
before_action :current_user
# POST /orders
def create
order = @user.orders.create!(order_params)
if order
render json: order
else
render json: order.errors
end
end
private
def order_params
params.permit(:price)
end
def current_user
@user ||= User.find(params[:user_id])
unless @user
render json: user.errors
end
end
end根據 REST 設計最佳實踐,我們使用 nested resource ,因此將 user_id 作為參數傳遞,並看到我們在 OrdersController 裏面聲明 before_action :current_user ,這意味著在以下場景中,方法current_user 將首先被執行,最後執行 controller 的 action,如此一來若有很多 action 就不會有重複的程式碼產生。
before_action 可以通過 render 隨時中斷執行,以 current_user 方法為例,如果沒有匹配 user_id 參數的用戶,那麼它將使用 render 方法傳回錯誤,因此 controller 的 action 將永遠不會執行,通過同樣的邏輯,我們可以確定如果 action 被執行,那麼會存在一個@user實例變量提供我們在 action 中使用。
建立 Routes
Rails 會根據 config/routes.rb 這個檔案的內容,從客戶端接收 HTTP 請求並將請求轉發到相應 controller 中定義的 action。
開啟 config/routes.rb,為我們的 API 指定 Route,如下:
# config/routes.rb
Rails.application.routes.draw do
get '/users/:id', to: 'users#show'
post '/users', to: 'users#create'
post '/users/:user_id/orders ', to: 'orders#create'
# Define your application routes per the DSL in https://guides.rubyonrails.org/routing.html
# Defines the root path route ("/")
# root "articles#index"
end檢查列出現有 routes 列表,請在 terminal 中執行以下命令:
rails routes --expanded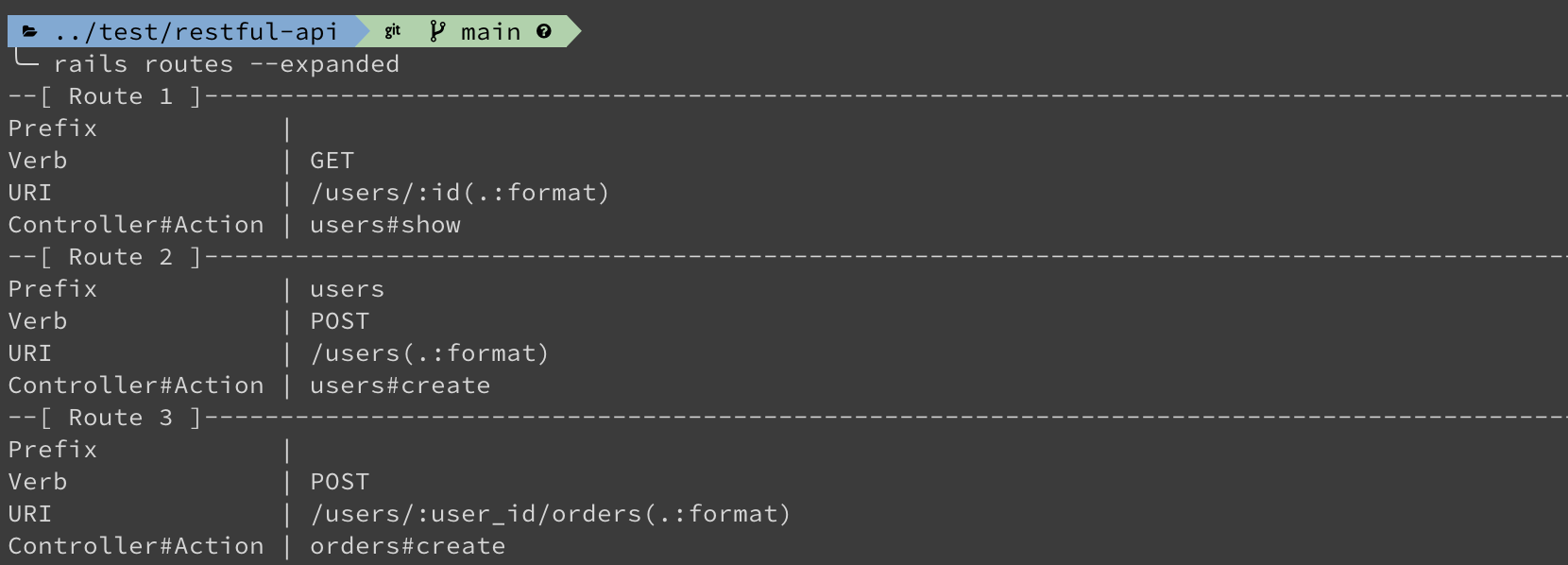
測試我們的 API
現在,為了檢查結果我們將使用 Postman 工具進行測試,在測試之前,首先啟動開發 Rails server Rails 框架提供了一個內置的 server 工具,可以使用 rails server 命令運行,執行以下命令:
rails server -p 3000設定 Postman 環境變數
通常,環境變數可以支援在讓開發者不同環境下使用不同的參數來進行測試全部的測試,畢竟很多時候開發者會先使用 Postman 測試 API 是否正常,但是若要在掌握不同環境(Testing、Staging ⋯⋯)各個階段環境測試,又會是大幅度的更動,因此使用環境變數是可以在請求中使用的一組變量,簡化測試的調整幅度,也可以幫助團隊成員對共享數據的訪問。
- 開啟 Postman 點選左側選單 Environments
- 建立新環境變數,點選 +
- 定義一組
server變數為 API 的端點http://localhost:3000 - 將設定的環境變數資料儲存,點選畫面中的 Save
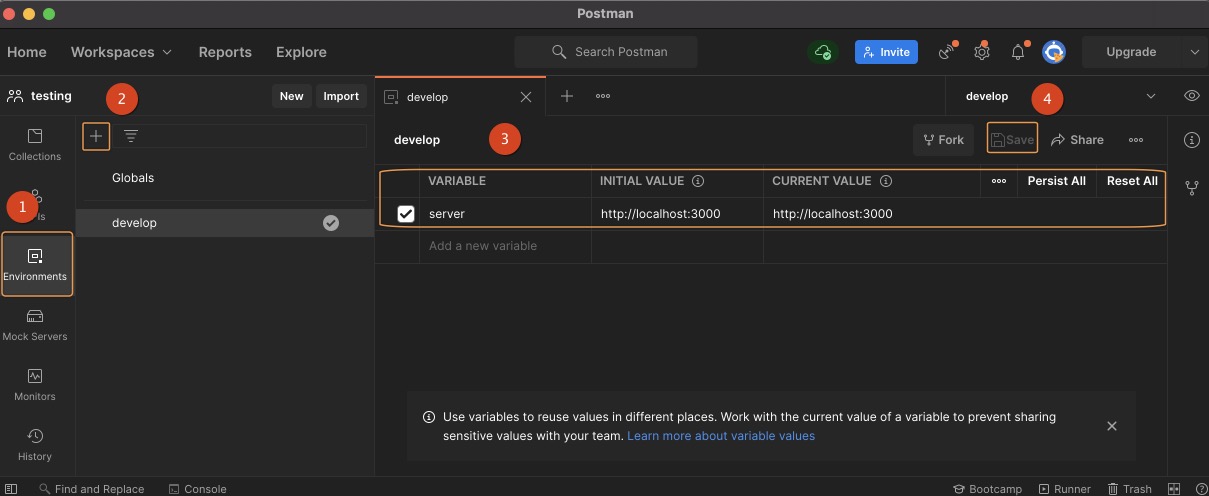
測試 API 結果
- 回到 Collections 建立 request 並選擇介面中 (1) 的位置,宣告當前的環境
develop - 設定發出
POST請求以及帶入環境變數{{server}}呼叫建立用戶的位置並傳遞建立資料 - 點選 Send 測試建立用戶的 API
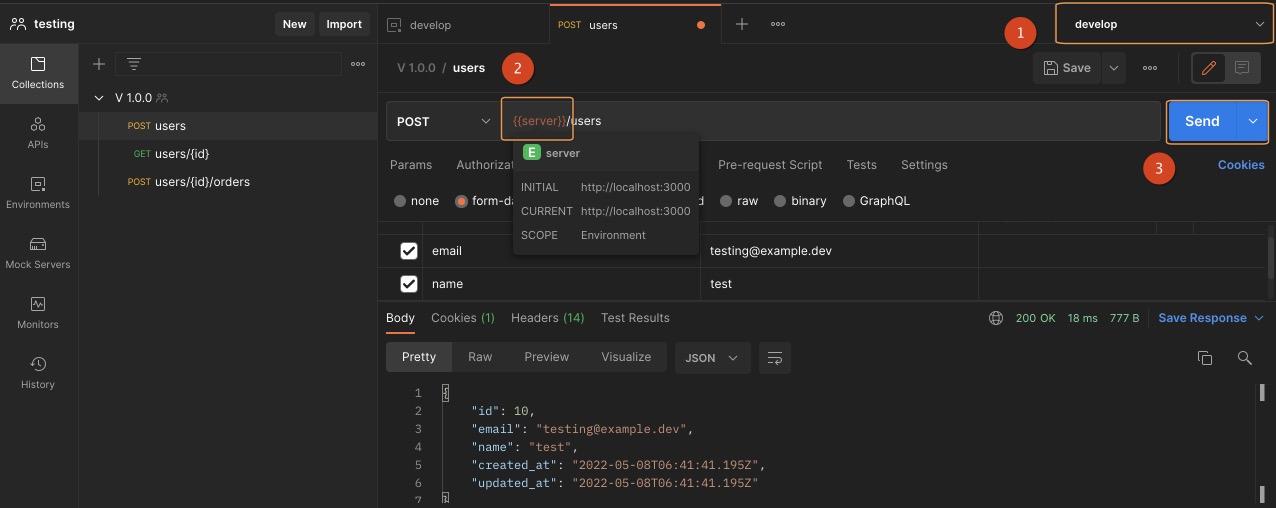
在上面的示例中,提出了一個請求 POST /users 將建立一筆新的用戶記錄,如畫面中 Response 的部分可以看到建立的用戶紀錄,就代表已成功完成新增。
到目前為止,Postman 仍然是我個人對在 API 上運行手動測試的偏好,它簡化了構建 API 的每個步驟,以及輕鬆生成文件檔案,讓開發者除了在開發 API 及編寫規範之外,手動測試以讓我們確定 API 是否符合預期。
測試主要的目的是為了確保產出的品質,在測試過程中有很多細節或重複性的測試,以及有良好的測試涵蓋搭配 git push 前進行全部的測試,就會需要撰寫自動化的測試程式,也就是寫程式去測試程式,在之後的文章中再來描述使用 RSpec 來進行自動化測試。
結論
我們已經完成了一個使用 Rails 作為 API 數據處理的程式端,當然這只是基礎的建置,Rails 還提供許多的功能以及許多實用的工具,喜歡這框架的開發者可以再深入了解發掘更多。
不同語言的框架讓我從中學習到不同的知識與應用,依據專案需求,可以更有彈性選擇適合的程式語言,最後附上本篇使用的程式碼,可以在 GitHub 上找到。